Based on a Lightning Talk by: Bam Faboyede, Senior iOS Engineer @ InRhythm on September 26th 2023, as part of this summer’s InRhythm Propel Summit 2023

Overview

Accessibility in iOS is about creating an inclusive environment where all users can engage with your app, empowering them to navigate, understand, and interact effectively.
In this article, we’ll embark on a detailed exploration of iOS accessibility, encompassing its priority, NDA compliance, standards like MWABP and WCAG, auditing tools, recommendations, and the invaluable Accessibility Inspector. Let’s dive into the realm of iOS accessibility and understand why it’s crucial, not just from a compliance perspective but as a catalyst for innovation:
- Overview
- Priority: Making Accessibility A Necessity
- NDA Compliance: Legal And Ethical Accommodations
- Standards: MWABP And WCAG
- Accessibility Auditing Tools: Your Eyes And Ears
- Accessibility Auditing Recommendations: Improving User Experience
- Accessibility Inspector: A Lifesaver For Developers
- The InRhythm Propel Summit: Innovation In iOS Accessibility
- Closing Thoughts
Priority: Making Accessibility A Necessity

Accessibility in iOS isn’t an optional feature; it’s a fundamental right for every user. It addresses the needs of individuals with various disabilities, including but not limited to visual, auditory, and motor impairments. Prioritizing accessibility ensures that everyone can benefit from your app’s functionalities, and it’s not just about compliance; it’s about ethical app development. Building accessibility features from the ground up should be part of your core design philosophy.
NDA Compliance: Legal And Ethical Accommodations
Besides being an ethical requirement, accessibility in iOS also has legal implications. Many countries have enacted laws or regulations that mandate digital accessibility. The Americans with Disabilities Act (ADA) in the United States is an example of such legislation. Ignoring these legal obligations can result in serious consequences, including lawsuits and damaged reputations.
Standards: MWABP And WCAG
The Mobile Web Application Best Practices (MWABP) and Web Content Accessibility Guidelines (WCAG) are the gold standards for ensuring the accessibility of digital content, including mobile apps. MWABP outlines best practices for mobile web applications, while WCAG offers a broader set of guidelines for web content in general. Complying with these standards is essential in making your iOS app accessible.
Accessibility Auditing Tools: Your Eyes And Ears
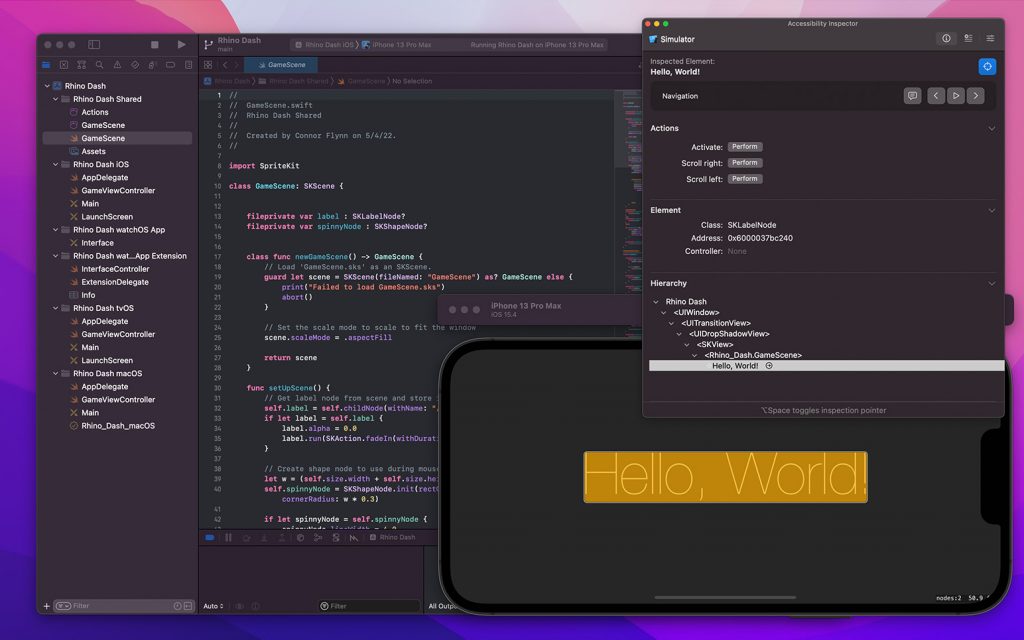
Auditing your iOS app for accessibility is a crucial part of the development process. Fortunately, there are various tools available to assist in this endeavor. Some of the most prominent ones include:
- VoiceOver
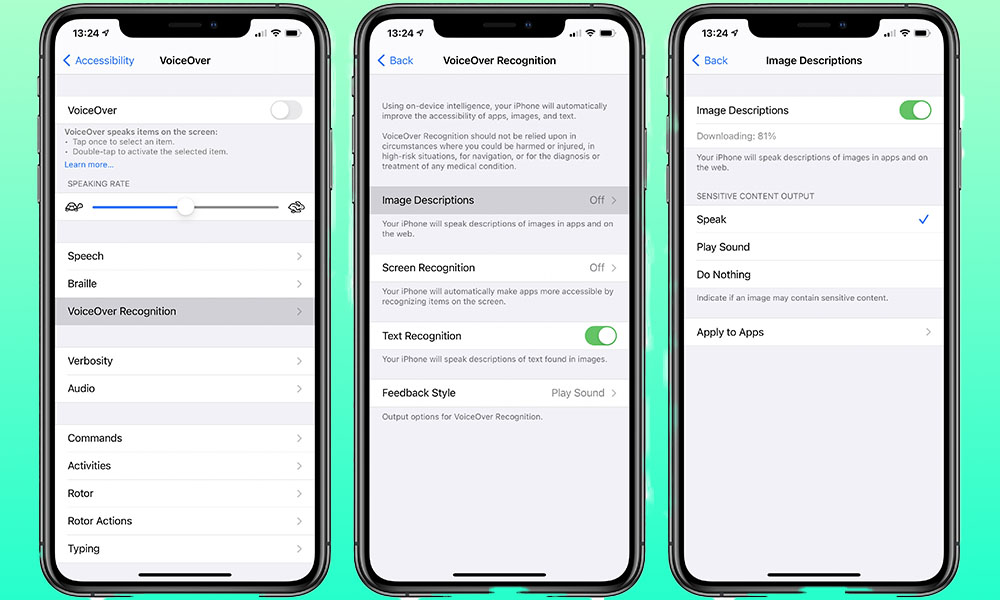
A built-in screen reader that reads the screen aloud to the user.
- TalkBack

The Android equivalent of VoiceOver.
- Color Contrast Analyzers
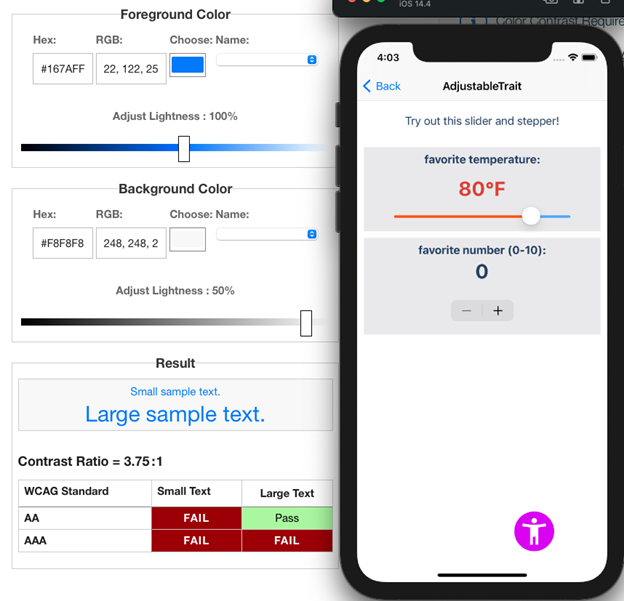
Tools to ensure text has adequate contrast against its background for visually impaired users.
- Keyboard Navigation Testing
Verifying that all functions are accessible via keyboard shortcuts.
Accessibility Auditing Recommendations: Improving User Experience
Auditing tools are useful not just for identifying accessibility issues but also for providing recommendations to fix them. These recommendations often include adjusting elements for VoiceOver compatibility, enhancing color contrast, labeling UI elements for screen readers, and ensuring proper focus management for keyboard navigation.
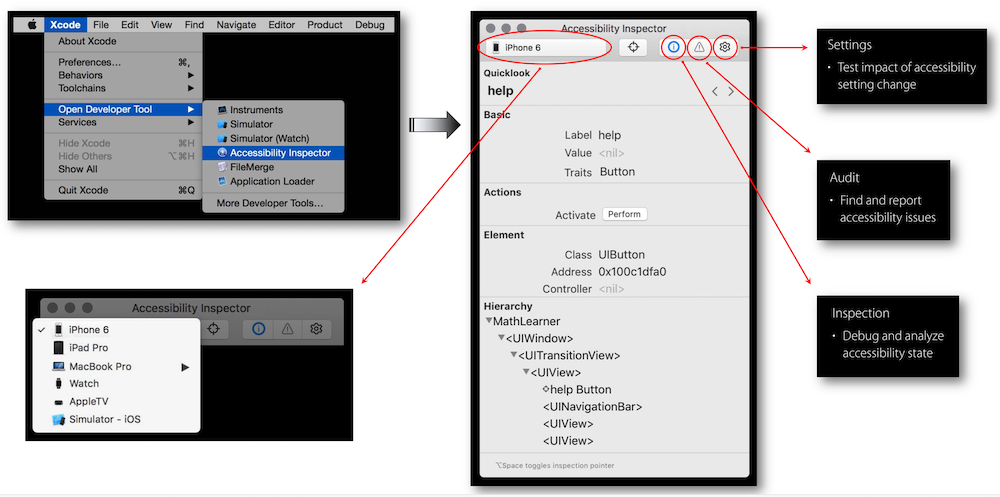
Accessibility Inspector: A Lifesaver For Developers

The Accessibility Inspector in Xcode is a developer’s best friend when it comes to iOS accessibility. This tool allows developers to inspect elements and see how they would be perceived by assistive technologies. It offers a detailed look at an app’s accessibility hierarchy, allowing for debugging and remediation of accessibility issues.
The InRhythm Propel Summit: Innovation In iOS Accessibility

The InRhythm Propel Summit embodies our unwavering commitment to learning, innovation, and excellence in the tech industry. The iOS workshop within the summit, led by renowned experts in the field sheds light on accessibility and various other facets of iOS development. Our mission is to equip developers with the knowledge and skills they need to build applications that offer exceptional user experiences and foster innovation. The iOS workshop and the entire Summit serve as catalysts for propelling our industry forward, where technology enhances lives, making it more than just functional but integral to people’s well-being.
Closing Thoughts
Understanding and implementing accessibility in iOS is more than just a development requirement; it’s about creating an inclusive digital environment. It’s a moral and legal obligation, and it can serve as a catalyst for innovation in your app development. By prioritizing accessibility, complying with standards, utilizing auditing tools, and adhering to the recommendations provided, you’re not only making your iOS app accessible but also creating a better experience for all users.